
Reply
Monthly Archives: May 2026
Trying something new
A friend of mine is starting a new podcast/youtube thing. Normally I find these kinds of things entirely cringe but I want all my friends to do well. That thinking lead us to collaborate and build https://vtv.show Its a simple local events site to support his work on youtube in venice CA
Find more of his work at https://suprissa.com/
All your CDN are belong to US
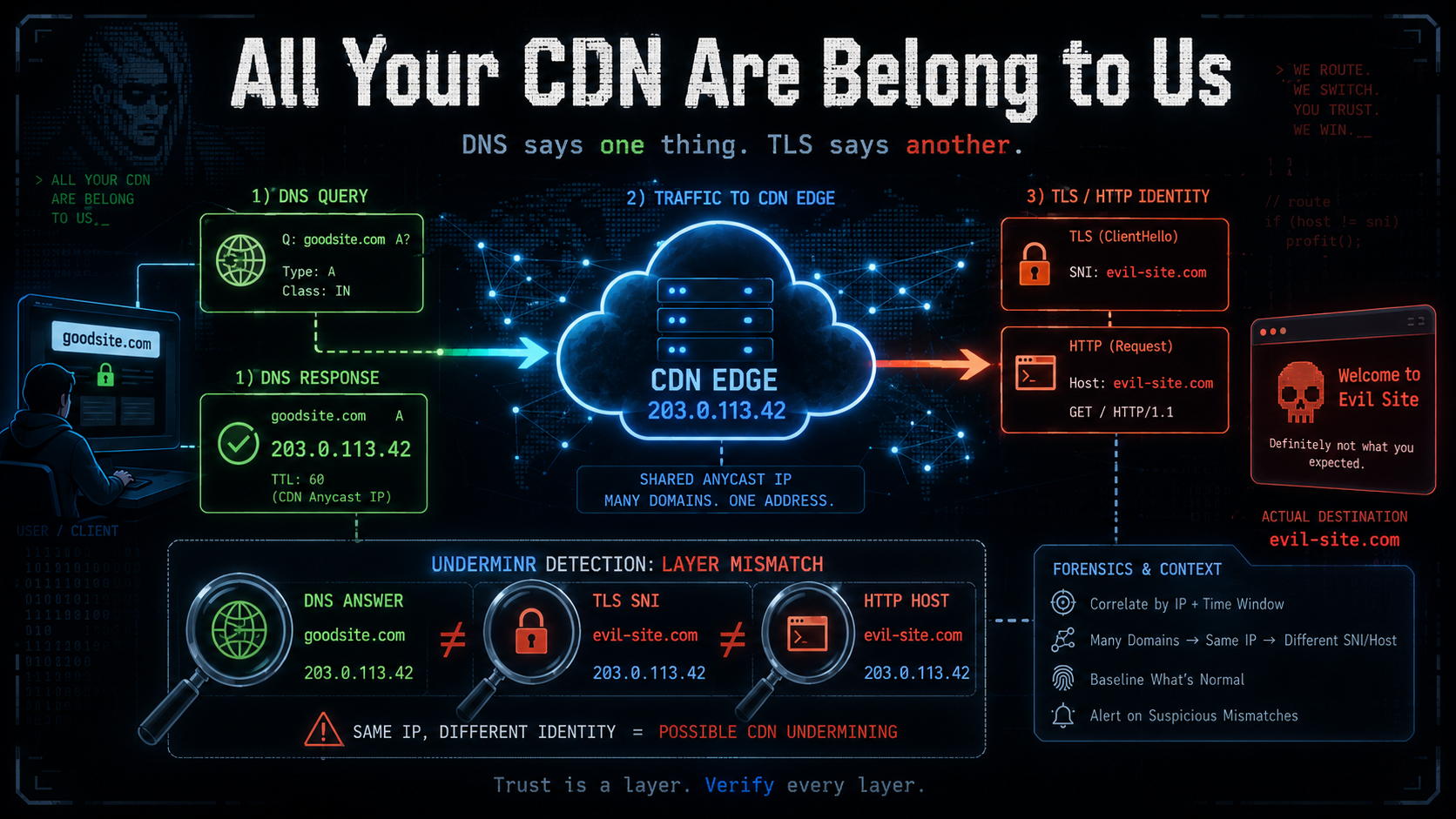
Underminr Detection: DNS Says One Thing, TLS Says Another
The detection story for Underminr is actually pretty simple, which is why it is so annoying.
You are not looking for some magic evil packet. You are looking for the layers of the connection telling different stories.
Normal web traffic looks something like this:
DNS: I want goodsite.comDNS answer: goodsite.com is at 104.x.x.xTLS: I am connecting to 104.x.x.xSNI: goodsite.comHTTP Host: goodsite.com
Everything lines up. Boring. Fine.
Underminr-style traffic looks more like this:
DNS: I want goodsite.comDNS answer: goodsite.com is at 104.x.x.xTLS: I am connecting to 104.x.x.xSNI: sketchy-domain.aiHTTP Host: sketchy-domain.ai
That is the trick.
The machine uses an allowed domain to get a perfectly valid CDN IP, then reuses that IP to talk to some other tenant living behind the same CDN.
DNSSEC does not really save you here, because the DNS answer can be totally legitimate. DNSSEC can prove that the DNS answer was authentic. Great. Congratulations. The lie happens later, at the TLS / HTTP / CDN routing layer.
So the detector has to correlate things across layers:
What DNS name did this endpoint ask for?What IP did DNS return?What IP did the endpoint connect to?What SNI did it present?What HTTP Host header did it use?Did that hostname ever get resolved normally?
In other words, you are looking for this mismatch:
Resolved: harmless-site.com -> CDN edge IPConnected to: CDN edge IPClaimed SNI: evil-site.com
That is the “oh come on” moment.
The really cursed version is when the attacker splits it into steps. First they make a clean-looking connection to the allowed domain, then they come back to the same CDN edge IP and swap the SNI / Host header to the real target.
So detection has to remember recent DNS answers and recent CDN connections per machine. It is not enough to look at one packet in isolation.
The direct-to-IP version is even more annoying because there may be no DNS lookup for the bad domain at all. Then the question becomes:
Why is this machine connecting directly to a shared CDN IPwhile presenting an SNI / Host name that it never resolved?
That is suspicious as hell.
And with ECH, because of course we needed one more layer of pain, the real SNI can be encrypted. At that point you need endpoint visibility, controlled DNS, policy around HTTPS / SVCB records, or some way to block or strip ECH in managed environments.
So the whole thing boils down to this:
DNS says one thing. TLS / HTTP says another. The CDN accepts both because shared edge infrastructure is a haunted house.
Honestly, it feels like Dan Kaminsky may have faked his own death and come back on the dark side.
Obviously joking. Mostly.
But this is exactly the kind of DNS-adjacent, “everything technically works as designed and that is the problem” nonsense that makes the internet beautiful and horrible at the same time.
The practical detection rule is basically:
For each endpoint: remember recent DNS answers: allowed-domain.com -> CDN_IP watch outbound TLS / HTTP: endpoint -> CDN_IP:443 SNI / Host = some-other-domain.com alert if: the CDN IP came from a recent allowed DNS answer but the SNI / Host does not match that DNS name and the SNI / Host name was not separately resolved in a normal allowed way
That is Underminr detection.
Not “block the IP,” because the IP is probably Cloudflare, Akamai, Fastly, or some other giant shared CDN edge.
Not “DNSSEC fixes it,” because DNSSEC only proves the DNS answer was real.
The actual problem is that the trust decision was made on one name, and the connection was later used for another name.
It is a cross-layer trust bug.
The internet has a lot of those.
Because apparently we enjoy pain.
Thoughts on the Mistakes of the Social Web

The internet was social before the social web. That part gets forgotten. People talked on IRC, forums, mailing lists, Usenet, AIM, Discord-style rooms, and all kinds of weird little places. The difference was that those places had context. You were not just “an account.” You were a person in a room, with some history, some reputation, and some reason for being there.
If you linked to your own thing in one of those spaces, people usually did not lose their minds as long as it was relevant. The question was not, “Did you make this?” The question was, “Is this useful here?” That is a much healthier standard. Sometimes the best link in the conversation is your own link because you are the person who wrote the thing, built the thing, documented the thing, or found the thing.
The social web broke that in a strange way. It created a huge opening for credibility fraud. Suddenly everyone could perform expertise, manufacture popularity, juice engagement, buy followers, write in brand voice, growth-hack sincerity, and pretend to be a participant while actually acting like a little attention-extraction machine. The feed turned normal human sharing into a suspicious transaction.
So now we live in this dumb world where links are both the blood vessels of the web and somehow treated like contraband. A web with no links is barely the web. It is just a set of private malls with recommendation engines and security guards. “Do not link to your own stuff” sounds noble until you realize it mostly helps people who are already big enough that other people link to them automatically.
PageRank made sense in a world where someone else might find your weird little page and link to it from their weird little page. That was the old bargain: publish something good, and the graph of the web slowly discovers it. But a lot of that middle layer is gone or weakened. Personal sites, blogrolls, directories, small forums, and independent linking culture got paved over by platforms. Now the system still wants backlinks, but the places where people actually gather often punish the behavior needed to create them.
That is one of the great little ironies of the modern web. The machine wants evidence that the world cares, but the world has been trained to treat public linking as spam unless it comes from someone already blessed by the machine. Nice little closed loop there. Very elegant. Completely cursed.
There is an important exception here: I am much less hostile to things like Bluesky, Mastodon, ActivityPub, AT Protocol, and other systems that at least try to make the social layer protocol-shaped instead of purely platform-shaped. That matters. Federation is not magic fairy dust, and protocol people can still be annoying in the very special way protocol people are annoying, but the architecture is pointed in a better direction.
A federated or protocol-based social system is not the same animal as a giant closed platform casino. If identity, distribution, clients, moderation, and hosting can be separated, then users are not trapped in quite the same way. The conversation can move. The client can change. The server can change. Communities can set local norms. The graph is not just locked in some corporate basement next to the engagement-optimization goblin.
That does not make every federated system good. It does not mean Bsky or Mastodon or anything else automatically solves the human problems. People can bring status games, mobs, spam, and weird little dominance rituals anywhere. Give humans a protocol and we will eventually find a way to argue about the chairs. But protocol-based social is at least trying to preserve some of what made the internet good: links, portability, interoperability, local context, and the possibility that no single company gets to be the landlord of human conversation.
So the problem is not “people talking online.” That would be an insane take. The internet is one of the best machines humans ever made for finding each other. The problem is the platform-owned social web: permanent, indexed, engagement-maximized, reputation-scored, and monetized within an inch of its life.
I understand why everyone built social features. In the pre-AI era, if you wanted a big site, users were the cheapest way to get content. Users wrote the posts, uploaded the photos, made the comments, tagged the pages, reviewed the restaurants, liked the posts, ranked the content, argued with each other, moderated each other, and generated the graph. The whole thing rode on the backs of users because paying people to produce and organize all that stuff was expensive as hell.
But that bargain had a cost. The user did not just contribute to the product. The user became the product, the inventory, the moderation problem, the credibility signal, and eventually the unpaid little hamster powering the engagement wheel.
And then because everything was public, permanent, indexed, and monetized, normal social behavior got weird. A casual thought became content. A disagreement became a searchable artifact. A joke became evidence. A person became a profile. A community became a growth channel. Human interaction got shrink-wrapped, barcoded, and stacked on a pallet in the warehouse of the feed.
I do think the social web has value. I am not saying people should stop talking online. But social interaction is often temporary, contextual, and messy. The web is durable, searchable, and decontextualized. Those are not naturally the same thing.
That mismatch is where a lot of the damage came from. We took ephemeral human behavior and made it permanent infrastructure. We took conversations that should have lived in rooms and put them on billboards. Then we acted surprised when everyone got performative, defensive, spammy, paranoid, or insane.
Maybe the healthier split is simple: let the web be good at durable reference, and let social be good at human context. Links, pages, sources, guides, documents, indexes — those belong on the web. Jokes, arguments, half-formed thoughts, “you had to be there” moments, and random social chatter probably belong somewhere smaller, softer, more local, or at least more portable than the giant engagement platforms.
AI changes the economics here. It may now be possible to build useful information systems without forcing users to generate the entire content layer. Machines can parse public sources, organize messy information, summarize, classify, dedupe, and turn scattered material into something usable. Humans can review and steer instead of being mined for every post, like, comment, and scrap of attention.
That does not mean AI slop should replace human culture. Please, God, no. The last thing we need is the web turning into a haunted vending machine full of synthetic LinkedIn posts. But it does mean we may not need to make every useful site into a little social casino anymore.
The mistake of the social web was not that people talked to each other. Talking is good. The mistake was turning talk into permanent content, content into ranking fuel, ranking into status, status into credibility, and credibility into a fraud market.
The web should have links. People should be allowed to point at things. Making something useful and saying “here, I made this” should not automatically be treated like some moral failure. That is how the web breathes.
A link-hostile web is an anti-web. It is a graph afraid of its own edges.
But a protocol-shaped social web? A federated web? A web where people can talk without every conversation becoming feed chum for the same giant machines?
That might be worth saving.
